Homogeneous model optimization using an evolutionary approach¶
In the previous tutorial, we used a grid search to fit the parameters of a homogeneous rWW model to the empirical data of our example subject. Here, we will use an evolutionary optimization approach for the same goal.
While grid search systematically samples the entire parameter space (at a predefined resolution), evolutionary optimizers explore the parameter space more selectively. They operate through a series of generations (or iterations) that iteratively move toward the optimal region. Typically, the optimization starts with a random distribution of particles across the parameter space. Each particle represents a set of parameters, for which a simulation is run and a cost is calculated based on the empirical target data. The cost function of the particles in one generation influences the sampling of the next generation, iteratively guiding the search toward regions that minimize the cost.
The cuBNM toolbox supports any optimizer implemented in the pymoo Python package (see the list here). However, it features the Covariance Matrix Adaptation Evolution Strategy (CMA-ES) as a selected optimization algorithm that has been shown to perform well in fitting brain network models (BNMs) [Wischnewski et al. 2022].
In this tutorial, we will run a CMA-ES optimization to fit the parameters of the same homogeneous rWW model used previously (with three free parameters: \(G\), \(w^{p}\), and \(J^{N}\)). The optimization will be allowed to run for a maximum of 120 generations with 128 particles (simulations) per generation, resulting in up to 15,360 simulations. However, the optimization will terminate earlier if convergence is achieved before reaching the maximum number of generations.
Running and saving the CMA-ES optimization¶
First, we’ll load the example structural connectivity (SC) and target empirical BOLD data, which is the same as the data used in the previous tutorials.
[1]:
from cubnm import datasets
# load structural connectome
sc = datasets.load_sc('strength', 'schaefer-100', 'group-train706')
# load empirical FC tril and FCD tril
emp_fc_tril = datasets.load_fc('schaefer-100', 'group-train706', exc_interhemispheric=True, return_tril=True)
emp_fcd_tril = datasets.load_fcd('schaefer-100', 'group-train706', exc_interhemispheric=True, return_tril=True)
Next, we define the simulation options, similar to those used in the grid search. To reduce the clutter in the printed output, here we set sim_verbose to False.
[2]:
sim_options = dict(
duration=900,
bold_remove_s=30,
TR=0.72,
sc=sc,
sc_dist=None,
dt='0.1',
bw_dt='1.0',
states_ts=False,
states_sampling=None,
noise_out=False,
sim_seed=0,
noise_segment_length=30,
gof_terms=['+fc_corr', '-fcd_ks'],
do_fc=True,
do_fcd=True,
window_size=30,
window_step=5,
fcd_drop_edges=True,
exc_interhemispheric=True,
bw_params='heinzle2016-3T',
sim_verbose=False,
do_fic=True,
max_fic_trials=0,
fic_penalty_scale=0.5,
)
We now define the optimization problem using BNMProblem, just as we did for the grid search.
[3]:
from cubnm import optimize
problem = optimize.BNMProblem(
model = 'rWW',
params = {
'G': (0.001, 10.0),
'w_p': (0, 2.0),
'J_N': (0.001, 0.5)
},
emp_fc_tril = emp_fc_tril,
emp_fcd_tril = emp_fcd_tril,
out_dir = './cmaes_homo',
**sim_options
)
Here we specified the model (model), the free parameters to explore along with their ranges (params), the empirical BOLD data we want to fit the simulations to (emp_bold), and the simulation options defined above (**sim_options).
We now create a CMA-ES optimizer (CMAESOptimizer) object and define its properties.
[4]:
cmaes = optimize.CMAESOptimizer(
popsize=128,
n_iter=120,
seed=1,
algorithm_kws=dict(tolfun=5e-3),
print_history=False
)
We plan to run a maximum of n_iter=120 iterations, with a population size of popsize=128 simulations/particles per iteration.
Since there is some randomness in how the optimizer samples the parameter space, we set a random seed=1 to ensure reproducibility. In practice, it is recommended to repeat CMA-ES runs with different seeds to avoid convergence to local optima.
The algorithm_kws argument specifies additional settings for the optimizer. Here, tolfun=5e-3 defines the tolerance for early stopping. If the cost function does not improve by more than 0.005 across recent generations or across the particles of the last generation, the optimization will terminate early. (For more details, see Hansen et al. 2016).
We also set print_history to False for a cleaner output in this tutorial. When it is set to True (default) while the optimization is run, the history of particles including their parameters and cost function components are printed.
Next, we assign the optimization problem to the CMA-ES optimizer cmaes using the setup_problem() method:
[5]:
cmaes.setup_problem(problem)
Then, run the optimization and save its results (Note that this will take a while):
[6]:
%%time
# run the optimization
cmaes.optimize()
# save the results
out_path = cmaes.save()
WARNING:cubnm.sim.base:Progress cannot be shown in real time when using Jupyter, but simulations are running in background. Please wait...
Initializing GPU session...
took 3.459390 s
Running 128 simulations...
took 39.584699 s
WARNING:cubnm.sim.base:Progress cannot be shown in real time when using Jupyter, but simulations are running in background. Please wait...
Current session is already initialized
Running 128 simulations...
took 39.506456 s
WARNING:cubnm.sim.base:Progress cannot be shown in real time when using Jupyter, but simulations are running in background. Please wait...
Current session is already initialized
Running 128 simulations...
took 39.513551 s
WARNING:cubnm.sim.base:Progress cannot be shown in real time when using Jupyter, but simulations are running in background. Please wait...
Current session is already initialized
Running 128 simulations...
took 39.507505 s
WARNING:cubnm.sim.base:Progress cannot be shown in real time when using Jupyter, but simulations are running in background. Please wait...
Current session is already initialized
Running 128 simulations...
took 40.114089 s
WARNING:cubnm.sim.base:Progress cannot be shown in real time when using Jupyter, but simulations are running in background. Please wait...
Current session is already initialized
Running 128 simulations...
took 39.571982 s
WARNING:cubnm.sim.base:Progress cannot be shown in real time when using Jupyter, but simulations are running in background. Please wait...
Current session is already initialized
Running 128 simulations...
took 39.736030 s
WARNING:cubnm.sim.base:Progress cannot be shown in real time when using Jupyter, but simulations are running in background. Please wait...
Current session is already initialized
Running 128 simulations...
took 39.797420 s
WARNING:cubnm.sim.base:Progress cannot be shown in real time when using Jupyter, but simulations are running in background. Please wait...
Current session is already initialized
Running 128 simulations...
took 40.952922 s
WARNING:cubnm.sim.base:Progress cannot be shown in real time when using Jupyter, but simulations are running in background. Please wait...
Current session is already initialized
Running 128 simulations...
took 39.666490 s
WARNING:cubnm.sim.base:Progress cannot be shown in real time when using Jupyter, but simulations are running in background. Please wait...
Current session is already initialized
Running 128 simulations...
took 39.620579 s
WARNING:cubnm.sim.base:Progress cannot be shown in real time when using Jupyter, but simulations are running in background. Please wait...
Current session is already initialized
Running 128 simulations...
took 39.814214 s
WARNING:cubnm.sim.base:Progress cannot be shown in real time when using Jupyter, but simulations are running in background. Please wait...
Current session is already initialized
Running 128 simulations...
took 40.232722 s
WARNING:cubnm.sim.base:Progress cannot be shown in real time when using Jupyter, but simulations are running in background. Please wait...
Current session is already initialized
Running 128 simulations...
took 39.686710 s
WARNING:cubnm.sim.base:Progress cannot be shown in real time when using Jupyter, but simulations are running in background. Please wait...
Current session is already initialized
Running 128 simulations...
took 39.779234 s
WARNING:cubnm.sim.base:Progress cannot be shown in real time when using Jupyter, but simulations are running in background. Please wait...
Current session is already initialized
Running 128 simulations...
took 40.951498 s
WARNING:cubnm.sim.base:Progress cannot be shown in real time when using Jupyter, but simulations are running in background. Please wait...
Current session is already initialized
Running 128 simulations...
took 40.942119 s
WARNING:cubnm.sim.base:Progress cannot be shown in real time when using Jupyter, but simulations are running in background. Please wait...
Current session is already initialized
Running 128 simulations...
took 40.680117 s
WARNING:cubnm.sim.base:Progress cannot be shown in real time when using Jupyter, but simulations are running in background. Please wait...
Current session is already initialized
Running 128 simulations...
took 40.305980 s
WARNING:cubnm.sim.base:Progress cannot be shown in real time when using Jupyter, but simulations are running in background. Please wait...
Current session is already initialized
Running 128 simulations...
took 39.772251 s
WARNING:cubnm.sim.base:Progress cannot be shown in real time when using Jupyter, but simulations are running in background. Please wait...
Current session is already initialized
Running 128 simulations...
took 39.683181 s
WARNING:cubnm.sim.base:Progress cannot be shown in real time when using Jupyter, but simulations are running in background. Please wait...
Current session is already initialized
Running 128 simulations...
took 39.833079 s
WARNING:cubnm.sim.base:Progress cannot be shown in real time when using Jupyter, but simulations are running in background. Please wait...
Current session is already initialized
Running 128 simulations...
took 40.676813 s
WARNING:cubnm.sim.base:Progress cannot be shown in real time when using Jupyter, but simulations are running in background. Please wait...
Current session is already initialized
Running 128 simulations...
took 39.755895 s
WARNING:cubnm.sim.base:Progress cannot be shown in real time when using Jupyter, but simulations are running in background. Please wait...
Current session is already initialized
Running 128 simulations...
took 40.655190 s
WARNING:cubnm.sim.base:Progress cannot be shown in real time when using Jupyter, but simulations are running in background. Please wait...
Current session is already initialized
Running 128 simulations...
took 39.737335 s
WARNING:cubnm.sim.base:Progress cannot be shown in real time when using Jupyter, but simulations are running in background. Please wait...
Current session is already initialized
Running 128 simulations...
took 40.945137 s
WARNING:cubnm.sim.base:Progress cannot be shown in real time when using Jupyter, but simulations are running in background. Please wait...
Current session is already initialized
Running 128 simulations...
took 40.680697 s
WARNING:cubnm.sim.base:Progress cannot be shown in real time when using Jupyter, but simulations are running in background. Please wait...
Current session is already initialized
Running 128 simulations...
took 39.503992 s
WARNING:cubnm.sim.base:Progress cannot be shown in real time when using Jupyter, but simulations are running in background. Please wait...
Current session is already initialized
Running 128 simulations...
took 39.620470 s
WARNING:cubnm.sim.base:Progress cannot be shown in real time when using Jupyter, but simulations are running in background. Please wait...
Current session is already initialized
Running 128 simulations...
took 39.728724 s
WARNING:cubnm.sim.base:Progress cannot be shown in real time when using Jupyter, but simulations are running in background. Please wait...
Current session is already initialized
Running 128 simulations...
took 39.759686 s
WARNING:cubnm.sim.base:Progress cannot be shown in real time when using Jupyter, but simulations are running in background. Please wait...
Current session is already initialized
Running 128 simulations...
took 39.736190 s
WARNING:cubnm.sim.base:Progress cannot be shown in real time when using Jupyter, but simulations are running in background. Please wait...
Current session is already initialized
Running 128 simulations...
took 39.832294 s
WARNING:cubnm.sim.base:Progress cannot be shown in real time when using Jupyter, but simulations are running in background. Please wait...
Current session is already initialized
Running 128 simulations...
took 39.798824 s
WARNING:cubnm.sim.base:Progress cannot be shown in real time when using Jupyter, but simulations are running in background. Please wait...
Current session is already initialized
Running 128 simulations...
took 40.952041 s
WARNING:cubnm.sim.base:Progress cannot be shown in real time when using Jupyter, but simulations are running in background. Please wait...
Current session is already initialized
Running 128 simulations...
took 39.571825 s
WARNING:cubnm.sim.base:Progress cannot be shown in real time when using Jupyter, but simulations are running in background. Please wait...
Initializing GPU session...
took 2.790161 s
Running 1 simulations...
took 28.803446 s
Rerunning and saving the optimal simulation(s)
WARNING:cubnm.sim.base:Progress cannot be shown in real time when using Jupyter, but simulations are running in background. Please wait...
Current session is already initialized
Running 1 simulations...
took 28.751414 s
CPU times: user 25min 57s, sys: 8.62 s, total: 26min 6s
Wall time: 27min 16s
We can see that the optimizer converged and stopped earlier than the specified maximum 120 iterations.
Note: At the end of the CMA-ES optimization (if convergence is reached), the algorithm samples a single final particle in the last generation, which represents its best estimate of the optimal point. However, the actual optimal simulation (cmaes.opt) is defined as the particle with the lowest cost across the entire optimization history (cmaes.history). As a result, the best estimate from the final generation and the true optimum found during the search may differ.
When cmaes.save() is called, the optimal simulation is re-run so that its simulated data can be saved to disk. Similar to the grid search, the simulated data, parameters and cost function components of the optimal simulation, as well as the optimizer history, simulation and optimization configurations (including SC and target FC/FCD) are saved to disk. For a detailed description of the saved files, see the grid search tutorial.
Visualization of the optimization history¶
The parameters of all simulations (particles) run during the optimization, along with their associated cost function and its components, are stored in cmaes.history.
[7]:
cmaes.history
[7]:
| index | G | w_p | J_N | cost | +fc_corr | -fcd_ks | +gof | -fic_penalty | gen | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 5.232492 | 1.069355 | 0.407682 | 1.144608 | 0.264236 | -0.917424 | -0.653187 | -0.491421 | 1 |
| 1 | 1 | 5.318735 | 0.855536 | 0.406241 | 1.135624 | 0.270156 | -0.915378 | -0.645222 | -0.490402 | 1 |
| 2 | 2 | 1.520055 | 0.944634 | 0.088201 | 0.401560 | 0.304679 | -0.704016 | -0.399337 | -0.002223 | 1 |
| 3 | 3 | 2.099185 | 1.589071 | 0.149400 | 1.141352 | 0.214289 | -0.926756 | -0.712468 | -0.428885 | 1 |
| 4 | 4 | 4.463698 | 1.864289 | 0.372126 | 1.202838 | 0.217721 | -0.926394 | -0.708673 | -0.494165 | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 4732 | 124 | 1.535664 | 0.008723 | 0.406681 | -0.124920 | 0.298578 | -0.139976 | 0.158602 | -0.033682 | 37 |
| 4733 | 125 | 1.537103 | 0.007536 | 0.408259 | -0.124749 | 0.298822 | -0.140347 | 0.158475 | -0.033726 | 37 |
| 4734 | 126 | 1.553229 | 0.001340 | 0.413155 | -0.123406 | 0.298909 | -0.140169 | 0.158740 | -0.035334 | 37 |
| 4735 | 127 | 1.549690 | 0.000119 | 0.407794 | -0.121235 | 0.298185 | -0.142155 | 0.156030 | -0.034795 | 37 |
| 4736 | 0 | 1.541306 | 0.006544 | 0.409849 | -0.124903 | 0.298873 | -0.139757 | 0.159116 | -0.034213 | 38 |
4737 rows × 10 columns
We can visualize how negative cost evolved over the course of CMA-ES optimization. Here, to indicate better simulations with higher values, rather than the cost function we will visualize negative cost function.
[8]:
cmaes.plot_history('-cost')
[8]:
<Axes: xlabel='Generation', ylabel='- Cost'>

We can also visualize how the particles moved through the 3D parameter space ('G', 'w_p', 'J_N') across generations. We will create a GIF showing the progression of particles over time.
[9]:
import matplotlib.pyplot as plt
import imageio
import os
import tempfile
free_params = ['G', 'w_p', 'J_N']
frames = []
temp_dir = tempfile.mkdtemp()
# using consistent color ranges and axes across frames
vmin = -cmaes.history['cost'].max()
vmax = -cmaes.history['cost'].min()
# loop through each generation and save a frame
for gen in range(cmaes.history['gen'].min(), cmaes.history['gen'].max() + 1):
# plot parameter space in current generation
fig, ax = plt.subplots(figsize=(5,5), subplot_kw={'projection': '3d'})
cmaes.plot_space(
'-cost',
title=f'Generation {gen}',
gen=gen,
config=dict(
alpha=0.6,
size=20,
vmin=vmin,
vmax=vmax,
zoom=0.85,
azim=120,
),
ax=ax
)
# save image
fig.tight_layout()
frame_path = os.path.join(temp_dir, f'frame_{gen}.png')
plt.savefig(frame_path)
frames.append(frame_path)
plt.close(fig)
# create the GIF
images = [imageio.imread(frame) for frame in frames]
imageio.mimsave('./cmaes_3d.gif', images, fps=2, loop=0)
/tmp/ipykernel_42854/1777437330.py:40: DeprecationWarning: Starting with ImageIO v3 the behavior of this function will switch to that of iio.v3.imread. To keep the current behavior (and make this warning disappear) use `import imageio.v2 as imageio` or call `imageio.v2.imread` directly.
images = [imageio.imread(frame) for frame in frames]

This visualization shows how over successive generations the particles are gradually concentrated into a specific region of the parameter space.
Visualization of the optimal simulation¶
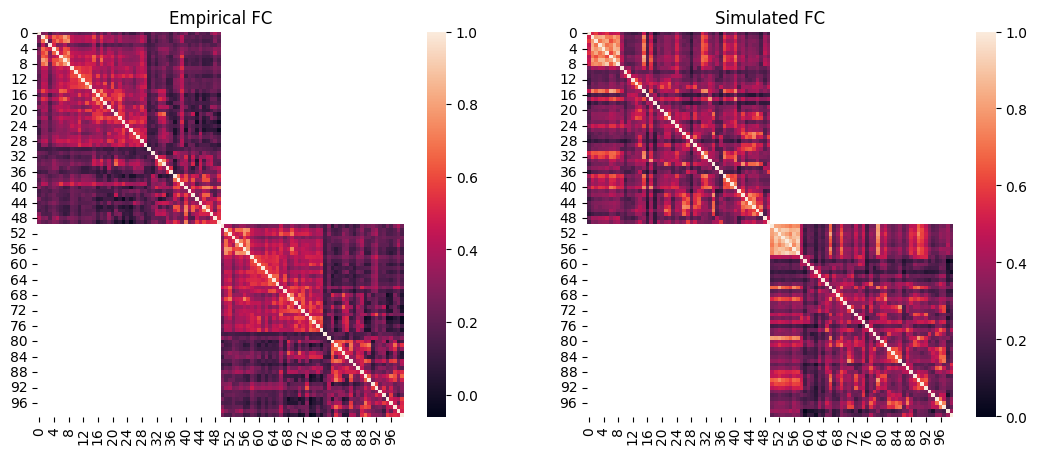
Lastly, we will visualize the simulated FC and FCD of the optimal simulation and compare them to the empirical data.
We can then plot the empirical FC next to the simulated FC. Note that at the end of the single-objective optimizations such as CMA-ES, cmaes.problem.sim_group contains a single simulation which is the optimum, therefore we can access its data by providing 0 as the simulation index.
[10]:
import seaborn as sns
# load the squared form of the empirical FC
emp_fc = datasets.load_fc('schaefer-100', 'group-train706', exc_interhemispheric=True, return_tril=False)
opt_idx = 0
# load squared form of optimal simulated FC
sim_fc = cmaes.problem.sim_group.get_sim_fc(opt_idx)
# plot it next to the empirical FC
fig, axes = plt.subplots(1, 2, figsize=(13, 5))
sns.heatmap(emp_fc, ax=axes[0])
axes[0].set_title("Empirical FC")
sns.heatmap(sim_fc, ax=axes[1])
axes[1].set_title("Simulated FC")
[10]:
Text(0.5, 1.0, 'Simulated FC')
[11]:
import scipy.stats
# regression plot
fig, ax = plt.subplots()
sns.regplot(
x=cmaes.problem.sim_group.sim_fc_trils[opt_idx],
y=emp_fc_tril,
scatter_kws=dict(s=5, alpha=0.2, color="grey"),
line_kws=dict(color="red"),
)
ax.set_xlabel("Simulated FC")
ax.set_ylabel("Empirical FC")
# calculate Pearson correlation
print(f"FC correlation = {scipy.stats.pearsonr(cmaes.problem.sim_group.sim_fc_trils[opt_idx], emp_fc_tril).statistic}")
FC correlation = 0.29902119224761026

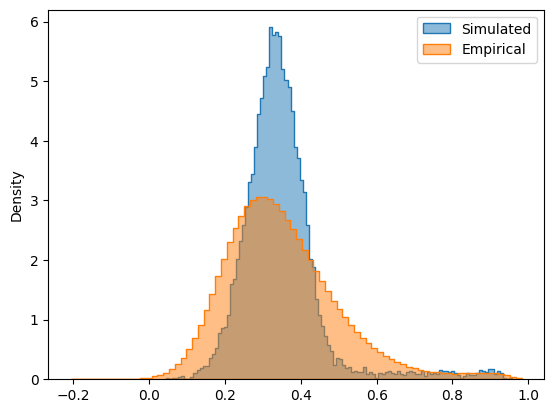
In addition to static FC, we can also plot the simulated FCD matrix distribution next to the empirical data, and calculate their Kolmogorov-Smirnov distance:
[12]:
# plot the distributions next to each other
sns.histplot(cmaes.problem.sim_group.sim_fcd_trils[opt_idx], element='step', alpha=0.5, label='Simulated', stat='density')
ax = sns.histplot(emp_fcd_tril, element='step', alpha=0.5, label='Empirical', stat='density')
ax.legend()
# calculate KS distance
print(f"FCD KS distance = {scipy.stats.ks_2samp(emp_fcd_tril, cmaes.problem.sim_group.sim_fcd_trils[opt_idx]).statistic}")
FCD KS distance = 0.13931505060977967
The simulated and empirical FC and FCD are quantitatively compared using the FC correlation (+fc_corr) and FCD KS distance (-fcd_ks). These metrics, along with the other cost function components and the parameters of the optimal simulation, are stored in cmaes.opt:
[13]:
cmaes.opt
[13]:
index 74.000000
G 1.546575
w_p 0.003553
J_N 0.411888
cost -0.125094
+fc_corr 0.299021
-fcd_ks -0.139315
+gof 0.159706
-fic_penalty -0.034612
gen 34.000000
Name: 4298, dtype: float64
We can observe that this optimal simulation has a lower cost function and higher goodness-of-fit compared to the optimal point found in the grid search tutorial. This shows the advantage of using evolutionary optimization algorithms over brute-force grid search. Evolutionary optimizers are not limited by a fixed sampling resolution, and rather, can explore parameter values more flexibly and precisely, allowing them to potentially reach better optima.
Note: This improved fit came at the cost of higher compute time. On an A100 GPU, the 1000-simulation grid search completed in ~3.5 minutes, while the CMA-ES optimization took nearly 10× longer. This is partly due to the sequential nature of evolutionary optimizers (generations can’t be run in parallel), and also because the total number of simulations here was ~5× higher. This raises the question: when working with a low-dimensional model where grid search is still feasible, might that be a more cost-effective choice?